データモデル¶
階層構造¶
GT.M は、階層型ツリーデータモデル を使用します。
GT.Mデータモデルは、インデックスとコンテンツのデータ型は、制限が何も無い階層型の連想記憶(多次元配列)に基づいています。
アプリケーションロジックは、その問題領域にふさわしい、スキーマ、辞書、データ編成を課すことができます。
ツリー¶
データは、「木の枝」にあたる部分に格納されます。
たとえば、次のように、Mの 階層型データベース で、銀行の取引用データを記憶する方法を表してみます。
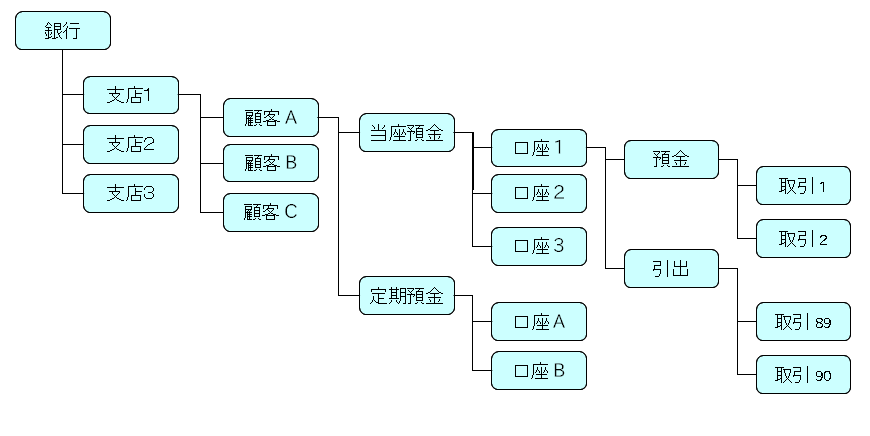
- 集合的な概念として、”銀行” からスタートすることに注意してください。
- 銀行は、複数の「枝」(例えば、別の市町村や地域のオフィス)があります。
- すべての「枝」には、複数の顧客があります。
- 顧客は(それぞれの複数個の)当座と定期の預金口座がある。
- 当座預金の口座で、顧客が預金と引出の両方を行います。
- 預金の収集は、日時と金額を記したトランザクション番号を持つ取引があります。
階層型データベース内のデータ構造での一般的な検索では、ツリー内の分岐パスに従うことを前提としています。
この場合、より一般的な要件は:
特定の顧客のすべての預金取引
あるいはより高度な要件として:
ある日時の範囲で、銀行全体で行われたすべての引出トランザクションを取得する
この両方のクエリは可能ですが、 特定の顧客の取引が他のすべての顧客の取引と一緒に同じテーブルに存在するのが リレーショナルデータベースと思われます。
しかし、最初の要件は、このツリーのアレンジではるかに効率的になります。
すべてのトランザクション·レコードが一緒に存在するので、 2番目のクエリは、リレーショナルデータベースより効率的になります。 1つは主張できましたが、しかし、 もし日付の積み重なりで、さらなる効率を望むのであれば、階層型モデルを依然として使用したでしょう、 ここで行ったように、最上部の枝は、銀行の支店によって、日付の代わりに分割されたでしょう。
比較¶
- 階層型データベースは、トピックに関連のある情報は、そのトピックのサブフィールドに格納されるという意味で、ドキュメントデータベースに似ている。
- 階層型データベースは、ノードとリレーションシップで構成されている点で、グラフデータベースと類似しているが、しかし、ノードとのリレーションシップの両方が、階層ツリーの「枝」として記憶されているという点では、グラフデータベースとは異なっている。
- リレーショナルモデルから階層型モデルに移行する時に、テーブルのプロパティ(フィールド)に存在しているもののほとんどは、ツリー内の「枝」のインデックスになる。