GT.Mデータベース構造(GDS)は、B-star tree (B*-tree) 構造と呼ばれるバランスのとれたツリー形式に基づいて階層的です。B*-tree は、インデックスまたはデータブロックのいずれかであるブロックを含みます。データブロックが実際にデータを保存している間、インデックスブロックは、データブロック内のデータの場所を見つけるために使用されるポインタを含みます。各ブロックには、ヘッダとレコードを含みます。各レコードには、キーとデータを含みます。
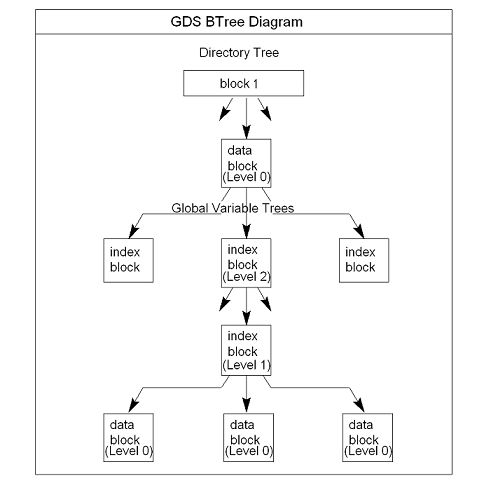
GDSは複数のB*-treesにデータを構造的に組み立てます。GT.Mは、アプリケーションが新しい名前のグローバル変数を定義するたびに、グローバル変数のツリー(GVT)と呼ばれる、新しいB*-treeツリーを作成します。各GVTは名付けられたグローバルのいずれかにデータを格納します、それは同じ添字なしグローバル名を共有するすべてのグローバル変数(GVN)です。例えば、グローバル ^A, ^A(1), ^A(2), ^A("A"), と ^A("B") は、同じGVTに格納されています。これらのグローバルのそれぞれが、同じ添字なしグローバル名、すなわち ^Aを共有することに注意してください。GVTは、インデックスとデータブロックの両方が含まれており、いくつかのレベルにまたがることができます。データブロックは、インデックスブロックがブロックの次のレベルを指示している間、実際のグローバル変数の値を含みます。
B*-tree 構造のルートでは、ディレクトリツリー(DT)と呼ばれる特殊なGDSツリーがあります。DTは、GVTへのポインタを含みます。 DT内のデータブロックは、添字なしのグローバル変数名とそのグローバル変数のGVTのルートブロックへのポインタを含みます。
treeの中のすべてのGDSのブロックは、レベル番号があります。レベルゼロ(0)は、ターミナルノード(すなわち、データブロック)を識別します。ゼロ(0)より大きいレベルは、非ターミナルノード(つまり、インデックスブロック)を識別します。各ツリーの最上位レベルは、ルートを識別します。すべての B*-trees は同じ構造を持っています。データベースのブロック1(1)は、常にディレクトリツリーのルートブロックを保持しています。
次の図は、GT.Mがグローバルを格納するために使用する内部GDS の B*-tree フレームワークを説明します。
データベースに以前出現されていない名前の接頭辞を持つ添字ありまたは添字なしグローバル変数を参照することにより、SETが添字なしグローバル名の最初の使用を生じさせる時には、GT.Mは新しいGVTを作成します。
![[重要]](images/important.jpg) |
重要 |
|---|---|
GVTは、それら添字なしの名前に関連付けられたすべてのノードがKILLされた後でさえも、存在し続けます。空のGVTは、無視できるスペースを占有し、GT.Mパフォーマンスには影響しません。しかし、あなたは多くの空のGVTを持っているので、もしパフォーマンスの問題に直面している場合、これらの空GVTを削除するには、MUPIP CREATE に続いて、MUPIP EXTRACTとMUPIP LOADを使用してデータベースファイルを再編成する必要があります。 |
次の各項では、データベース構造の詳細を説明します。
インデックスとデータブロックは、一連のレコードに続くブロックヘッダから成ります。ブロック・ヘッダには、情報を含む4つのフィールドがあります。第1フィールドは、2バイトで、ブロックのバージョンを指定します。第2フィールドは、2バイトで、ブロック内で現在使用されているバイト数を指定します。第3フィールドは、1バイトで、ブロック・レベルを指定します。最後(第4)フィールドは、8バイトで、ブロックが最後に変更されたときの、トランザクション数を表します。ブロックヘッダの解釈される形式は、次のようになります:
File /home/jdoe/.fis-gtm/V6.0-000_x86_64/g/gtm.dat Region DEFAULT Block 3 Size 262 Level 0 TN 3845EE V6
プラットフォームに応じて、適切なアライメントを生成するために充填文字(filler)を含んでいる空のフィールドもまたあるかもしれません。充填文字(filler)は、2番目と3番目のデータフィールドの間で発生し、7から8バイト増加しヘッダーの長さになります。
レコードは、レコードヘッダー、キー、ブロックポインタかグローバル変数名(GVN)の実際の値のいずれかで構成されています。レコードは、ノードとも呼ばれています。
レコードヘッダには、情報を含む2つのフィールドがあります。最初のフィールドは、2バイトで、レコードサイズを指定します。2番目のフィールドは、1バイトで、圧縮の数を指定します。
![[注意]](images/note.jpg) |
注意 |
|---|---|
GDSブロックヘッダと同様に、充填文字(filler)バイトは、プラットフォームに応じて、追加されるでしょう。 |
グローバル ^A("Name",1)="Brad" でのブロックの解釈される形式は、次のようになります:
Rec:1 Blk 3 Off 10 Size 14 Cmpc 0 Key ^A("Name",1)
10 : | 14 0 0 61 41 0 FF 4E 61 6D 65 0 BF 11 0 0 42 72 61 64|
| . . . a A . . N a m e . . . . . B r a d|
任意のインデックスブロック内のレコードのデータ部分は、4バイトのブロックポインタで構成されています。ディレクトリツリー内のレベル0 データもまた、4バイトのブロックポインタから構成されています。グローバル変数のTree の中のレベル0データは、グローバル変数名の実際の値で構成されています。
グローバル変数ノードは、その値のサイズが1つのデータベースブロックを超える場合、複数のブロックにまたがります。このようなグローバル変数ノードは、「スパニング・ノード」と呼ばれます。たとえば、^a が1つのデータベース・ブロックを超える値を保持している場合、GT.Mは、内部でキー ^a(#SPAN1) 、^a(#SPAN2) 、^a(#SPAN3) 、 ^a(#SPAN4) などのレコードの中で ^a の値に及んでいます。#SPAN1、#SPAN2、#SPAN3、#SPAN4 などは、特殊な添字であり、データベースには表示されますが、Mアプリケーション・レベルでは表示されません。GT.Mは、これらの特殊な添字を使用して、スパニング・ノードの順序を決定します。
最初の特殊な添字 #SPAN1 は、「特別インデックス("special index")」と呼ばれます。特別インデックスには、スパニング・ノードの値のサイズとその値を保持するために必要な追加レコードの数に関する詳細が含まれています。#SPAN2と残りのレコードは、スパニング・ノードの値のチャンクを保持します。バイナリ抽出のロード中に、GT.Mはこれらのチャンクを使用してグローバルの値を再構成します。これにより、ソース・データベースのブロックサイズがデスティネーション・データベースのブロックサイズと異なる場合に、グローバルの再スパンが可能になります。
|
注意 |
|---|---|
デスティネーション・データベースのブロック・サイズがキーと値を保持するのに十分な大きさである場合、グローバルはスパニング・ノードではありません(1つのデータベース・ブロックに収まるため) 。 |
1つのキーはグローバル変数名の内部の表現です。2つの鍵のバイト単位の比較では、グローバル変数ノードに定義された照合シーケンスに適合しています。照合シーケンスのデフォルトは、M標準規格で指定されたものです。照合シーケンスの定義の詳細については、 GT.Mプログラマーズガイド の "国際化" の章を参照してください。
圧縮カウントは、同じブロック内の以前のキーに共通するキーの先頭でバイト数を指定します。各ブロック内の最初のキーは、ゼロの圧縮カウントがあります。グローバル変数ツリーでは、ブロック内の最初のレコードのみ、ゼロの圧縮カウントを正しく持つことができます。
|
レコード キー |
圧縮カウント |
レコードの中のキーの結果 |
|---|---|---|
|
CUS(Jones,Tom) |
0 |
CUS(Jones,Tom) |
|
CUS(Jones,Vic) |
10 |
Vic) |
|
CUS(Jones,Sally) |
10 |
Sally) |
|
CUS(Smith,John) |
4 |
Smith,John) |
前の表では、M表現のキーを示しています。内部表現の説明については、key のセクションを参照してください。
レコードキーの非圧縮の部分は、レコードヘッダーの直後に続きます。レコードのデータ部分はキーに続き、2つの null(ASCII 0)バイトでキーから分離されています。
GT.Mは、現在のキーより字句的(辞書的)に大きいまたは等しいブロック内の最初のキーを見つけることによってレコードの位置を探します。もしブロックがゼロ(0)のレベルを持っている場合、位置は、当該レコードのそれか、当該レコードが存在しない場合に(辞書的に)次のレコードのそれかのどちらかです。もしブロックがゼロ(0)より大きいレベルを持っている場合、レコードは検索する次のレベルへのポインタを含んでいます。
GT.Mは、インデックスブロック内のキーは次のレベルでの実際に存在するキーに対応する必要はありません。
各インデックスブロック ( *-record) 内の最後のレコードは、*-key ("star-key") を含んでいます。 *-key は、Mの照合シーケンスの最後に利用可能な値を表している長さゼロのキーです。 *-keyは、ゼロ(0)のキーサイズを持つ、レコードヘッダとブロックポインタのみで構成される、最小の利用可能なレコードです。
*-keyは、次のような特徴があります:
7バイトまたは8バイトのレコードサイズ(エンディアンに依存)
3バイトまたは4バイトのレコードヘッダのサイズ(エンディアンに依存)
ゼロ(0)バイトのキーサイズ
4バイトのブロックポインタのサイズ
キーには名前の部分とゼロ以上の添字が含まれています。GT.Mは、文字列や数値のために異なった添字をフォーマットします。
ディレクトリツリー内のキーは、添字なしグローバル変数名を表します。グローバル変数のツリーのキーとは異なり、ディレクトリツリーのキーは、添字を含めてはいけません。
単一のヌル(ASCII 0)バイトは、変数名と添字のそれぞれを分離します。2つの連続したnull バイトはキーを終了します。GT.Mは、異なっている文字列の添字と数値添字をエンコードします。
ブロックの分割中に、システムはフォームの数値であるが正しい数値に対応していない添字を含むインデックスキーが生成されるでしょう。照合シーケンスの中で適切な場所に落ちるので、キーは、インデックスの処理に役立ちます。DSEがこれら"illegal:不正" の数値を表すとき、添字のために多くのゼロ桁が表示されます。
GT.Mは、0から255までの8ビットコードの可変長シーケンスとして、文字列の添字を保存します。プロセスの起動時にUTF-8の指定では、GT.Mは、Unicodeでエンコードされている 0から255までの8ビットコードの可変長シーケンスとして、文字列の添字を保存します。
照合シーケンスを保持しながら、数値と文字列を区別するには、GT.Mは、すべての文字列の添え字の前に16進FFを含んでいるバイトを追加します。グローバル変数 ^A("Name",1)="Brad" の形式での解釈は、次のようになります:
Block 3 Size 24 Level 0 TN 1 V5
Rec:1 Blk 3 Off 10 Size 14 Cmpc 0 Key ^A("Name",1)
10 : | 14 0 0 61 41 0 FF 4E 61 6D 65 0 BF 11 0 0 42 72 61 64|
| . . . a A . . N a m e . . . . . B r a d|
16進 FF は添字 "Name"の前にあることに注意してください。GT.Mは、キーで有効な文字の完全な範囲の使用を許可します。したがって、nullL(ASCII 0)は文字列の中で利用可能な文字です。GT.Mは、0x00 を 0x0101へのマッピングと0x01 を 0x0102 へのマッピング によって埋め込まれた null で文字列を処理します。 GT.Mは、エスケープコードとして0x01 を扱います。これは、null がキーに使用されている場合の混乱を解決し、同時に、適切な照合シーケンスを維持します。次の規則は、文字の表現に適用されます。
00 と 01 を除くすべてのコードは、対応するASCII値を表します。
00 はターミネータです。
01 は、以下のように、次のコードを変換するためのインジケータです:
|
コード(Code) |
意味(Means) |
ASCII |
|---|---|---|
|
01 |
00 |
<NUL> |
|
02 |
01 |
<SOH> |
指定されたUTF-8文字セットでは、解釈される出力は、すべての図形文字と不正文字ではドット文字(ピリオド)が表示されます。たとえば、グローバル変数 ^DS=$CHAR($$FUNC^%HD("0905"))_$ZCHAR(192) の内部表現は、次のようになります:
Rec:1 Blk 3 Off 10 Size C Cmpc 0 Key ^DS
10 : | C 0 0 0 44 53 0 0 E0 A4 85 C0 |
| . . . . D S . . ?. |
注意:DSEは wellformed文字(整形式) を表示しますか?DSEは、$CHAR($$FUNC^%HD("0905")) で wellformed文字(整形式) を、と、不正文字 $ZCHAR(192) でドット文字を表示することに注意してください。
指定されたM文字セットでは、解釈される出力は、すべての非ASCII文字と不正文字ではドット文字(ピリオド)が表示されます。
数値添字の形式は次のとおりです:
[ sign bit ] [ biased exponent ] [ normalized mantissa ] [符号ビット] [バイアスされた指数] [正規化された仮数部]
符号ビット(sign bit)、バイアスされた指数(biased exponent)は、一緒に、数値添字の最初のバイトを形成します。ビット7 は符号ビットです。ビット<6:0>は、指数を構成します。1つの null(ASCII 0)バイトの添字ターミネータの前にある残りのバイトは、可変長の仮数部(normalized mantissa)を表します。以下の説明では、GT.Mがその内部フォーマットに各数値の添字タイプを変換する方法を理解する方法を示しています。
ゼロ(0)添字(特殊ケース)
16進の値 80 (hex)を持つ単一バイトとしてゼロを表し、他の変換を必要としません。
仮数
指数を調整することによって正規化します。
パック10進表現を作成します。
もし数が奇数個ならば、仮数にゼロ(0)を追加します。
仮数内の各バイトに1(1)を追加します。
指数
添字の最初のバイトに指数を格納します。
16進 3F を追加することにより、バイアス指数。
結果の指数は、もし正の場合 3F から 7D の16進の範囲に、もし負の場合はzero (0) から 3E の16進の範囲に落ちます。
符号
符号処理のための準備で、指数部の符号 ビット<7> をセットします。
もし仮数が負の場合:その1の補数へ添字(指数を含む)の各バイトを変換し、仮数部に16進
FFを含んでいるバイトを追加します。
例えば、グローバル ^NAME(.12,0,"STR",-34.56) の解釈表現は、次のようになります。
Rec:1 Blk 5 Off 10 Size 1A Cmpc 0 Key ^NAME(.12,0,"STR",-34.56)
10 : | 1A 0 0 61 4E 41 4D 45 0 BE 13 0 80 0 FF 53 54 52 0 3F|
| . . . a N A M E . . . . . . . S T R . ?|
24 : | CA A8 FF 0 0 31 |
| . . . . . 1 |
CA A8 の補数表現は 35 57 で、次に、仮数部の内の各バイトから1つ(1)減算する時には、34 56を取得することに注意してください。
同様に、^NAME(.12,0,"STR",-34.567) の解釈表現は、次のようになります。
Rec:1 Blk 5 Off 10 Size 1B Cmpc 0 Key ^NAME(.12,0,"STR",-34.567)
10 : | 1B 0 0 9 4E 41 4D 45 0 BE 13 0 80 0 FF 53 54 52 0 3F|
| . . . . N A M E . . . . . . . S T R . ?|
24 : | CA A8 8E FF 0 0 32 |
| . . . . . . 2 |
奇数桁の数があるので、GT.Mは、仮数部にゼロ(0)を付加し、仮数部内の各バイトに1(1)を付加することに注意してください。